Языковые модели имеют проблемы с логикой

Проблемы логики у языковых моделей (LLM)
Недавнее исследование выявило значительные недостатки в логических способностях даже самых современных языковых моделей. Статья «Алиса в Стране чудес» подчеркивает, что при решении даже простых логических задач эти модели демонстрируют крайне низкую эффективность. Эксперты обнаружили, что даже крупные и продвинутые модели не справляются с элементарными задачами на уровне начальной школы, что подвергает сомнению их способность к надежному базовому рассуждению. Данное исследование ставит под вопрос общепринятые представления о функциональности языковых моделей и подчеркивает необходимость дальнейших исследований в этой области.
Процесс оценки и выявленные проблемы
Проведенное исследование выявило существенное снижение функциональных и логических способностей современных языковых моделей, несмотря на их описание как фундаментальных моделей, способных успешно выполнять различные задачи. Примером такого снижения стала простая задача на здравый смысл (проблема AIW), которую модели решали с затруднениями. Несмотря на высокие оценки в стандартизированных тестах, модели не смогли адекватно решить задачу, показав сильные колебания и низкую частоту правильных ответов. Эти результаты заставляют сомневаться в истинной компетентности языковых моделей и открывают необходимость дальнейших исследований для понимания и устранения базовых недостатков в их рассуждениях.
Примеры неверных ответов и псевдологические аргументы
Исследование показало, что языковые модели, такие как LLM, имеют серьезные проблемы с логическим мышлением. Примером этому служит задача "проблемы AIW", в которой модели не смогли правильно решить даже самую простую логическую задачу о количестве сестер у брата Алисы. Несмотря на использование различных комбинаций чисел и подсказок, модели демонстрировали низкую эффективность и часто приходили к неверным выводам. Даже после вмешательства исследователей, модели продолжали уверенно подтверждать свои ошибочные ответы, предлагая псевдоразумные аргументы в их поддержку. Эти результаты подчеркивают не только проблемы с логическим мышлением языковых моделей, но и необходимость дальнейших исследований в этой области.
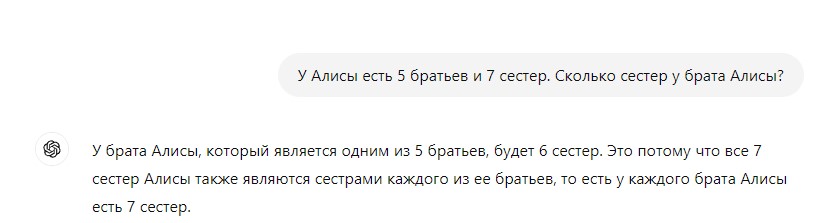
Неэффективность стандартных вмешательств
Стандартные методы вмешательства, предназначенные для исправления неправильных решений языковых моделей, оказались неэффективными в их обучении. Улучшенные подсказки и многоэтапные переоценки не помогали моделям добиться высокой точности ответов. Даже при увеличении масштаба моделей, средняя частота правильных ответов оставалась ниже 50%, хотя модели более крупного размера продемонстрировали немного лучшие результаты. Это указывает на то, что на сегодняшний день языковые модели сталкиваются с серьезными проблемами в базовых рассуждениях, несмотря на представляемые об их высокой функциональности.
Вопросы о будущем использования LLM
Согласно недавнему исследованию, языковые модели, даже самые продвинутые, имеют проблемы с логическими рассуждениями. Простейшая задача на здравый смысл, как «проблема AIW», оказалась вызывающей серьезные затруднения для большинства LLM. Даже при увеличении масштаба моделей, их способность к надежному рассуждению значительно подводила, оставляя сомнения в общей компетентности моделей в основных задачах. Эти выводы ставят под сомнение широкое использование LLM в контекстах, где требуются базовые логические рассуждения, что требует дальнейших исследований для понимания и устранения недостатков в их функционировании.
Заключение
В результате проведенного исследования эксперты выявили значительные недостатки в логических способностях современных языковых моделей (LLM), даже самых продвинутых. Например, при решении элементарных логических задач такие модели демонстрируют неожиданно низкую эффективность. Это вызывает необходимость дальнейших исследований, чтобы понять причины и механизмы, по которым текущие модели испытывают сложности с базовыми задачами. В свете таких выводов становится ясной необходимость переоценки возможностей языковых моделей и разработки новых стандартизированных тестов для более точной оценки их интеллектуальных способностей.