Несколько LLM соперничают, но ни одна не лидирует

Консолидация и выравнивание конкуренции
На начало марта 2025 года рынок больших языковых моделей (LLM) демонстрирует заметное выравнивание конкуренции. Это явление стало возможным благодаря консолидации финансовых ресурсов, технологий и интеллектуальных вкладов ведущих специалистов, что в свою очередь создало динамичный темп научно-технического прогресса в области AI. Развитие передовых LLM детейлировано процессами, близкими к пределу возможностей текущих архитектур, что усложняет определение однозначного лидера среди моделей. В отличие от яркого технологического рывка 2023 года, сейчас ни одна разработка не обладает значительными преимуществами, что указывает на то, что многие компании достигли схожего уровня развития. Такой ритм технологических обновлений ведет к более жесткой конкурентной среде, где единственным критерием успеха становится не только инновационность, но и способность моделей решать задачи с высокой точностью и стабильностью.
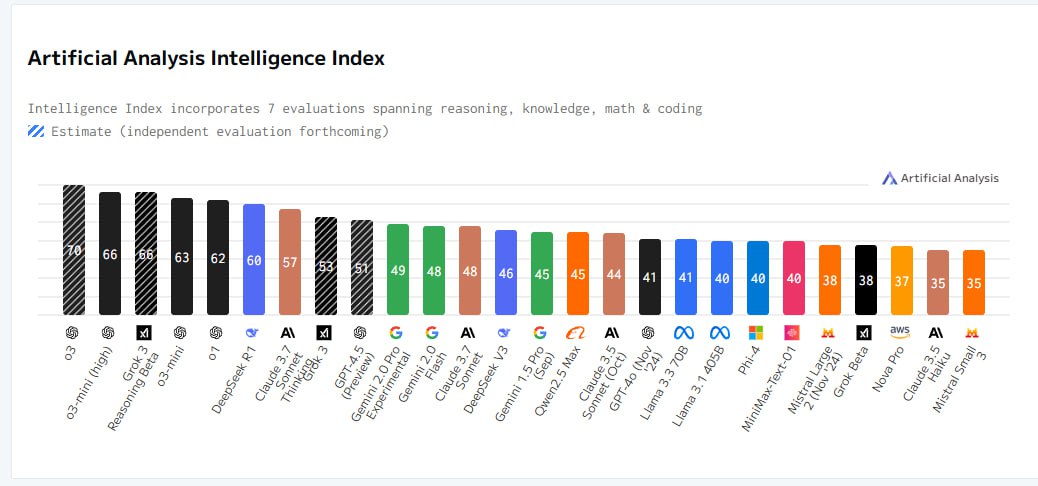
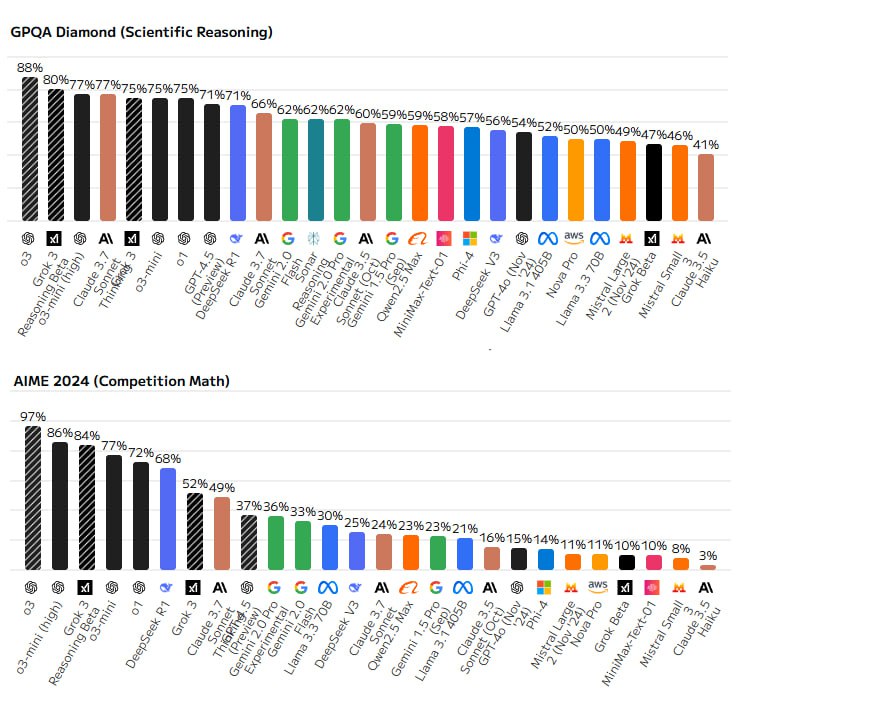
Пределы развития и проблемы GPT-4.5
С осени 2024 года на фоне стремительного развития технологий LLM стало очевидно, что ни одна из моделей не обладает значительными преимуществами, как это наблюдалось в первых этапах технологического прорыва в 2023 году. GPT-4.5, хотя и демонстрирует высокие результаты в тестах, не выделяется на фоне своих конкурентов, что вызывает настороженность относительно достижения предела в развитии. На практике внедрение этой модели сопровождается неоднозначными отзывами: несмотря на рекордную стоимость, она не обеспечивает удовлетворительных конкурентных преимуществ. Дорогостоящая цена в 30 раз выше средней по рынку вызывает вопросы о её реальной эффективности и целесообразности использования, особенно учитывая, что многие соперники предлагают схожие или даже лучшие результаты. Таким образом, ситуация на рынке LLM поднимает важные вопросы о будущем развития и перспективах модели GPT-4.5.
Роль рассуждающих моделей
Рассуждающие модели, такие как DeepSeek R1, становятся все более популярными благодаря своей способности эффективно решать сложные логические задачи. Используя метод «цепочки мыслей» (Chain of Thought, CoT), эти модели разлагают задачи на несколько этапов, что позволяет им демонстрировать более высокую точность и стабильность в решении проблем, требующих логического анализа. Например, этот подход позволяет моделям успешно справляться с математическими задачами и головоломками, что значительно повышает их полезность в прикладных ситуациях.
Несмотря на то что GPT-4.5 остается одной из ведущих LLM, она не может соперничать с DeepSeek R1 в области рассуждений. Тем не менее, ее сильные стороны, такие как универсальность и возможность генерации "человекоподобных" ответов, продолжают привлекать внимание пользователей. GPT-4.5 востребована, особенно в тех случаях, когда не требуется глубокий логический анализ, что подчеркивает разнообразие потребностей пользователей на рынке и растущую необходимость в моделях, способных отвечать на различные запросы.
Лидеры среди рассуждающих моделей
На рынке рассуждающих моделей, которые применяют метод цепочки мыслей (CoT) для решения сложных задач, в начале марта 2025 года выделяются несколько заметных игроков. OpenAI o3-mini (high) занимает одну из лидирующих позиций благодаря мощным алгоритмам, несмотря на наличие более дорогой версии o3, доступной только по подписке. Grok 3 Reasoning демонстрирует выдающиеся результаты в большинстве тестов, подтверждая статус одной из лучших в мире LLM, в то время как DeepSeek R1, обладая высокой универсальностью, укрепляет свои позиции как ведущая китайская модель в мировом ТОП-3. Claude 3.7 Sonnet Thinking славится своими уникальными возможностями в программировании, хотя и не дотягивает до лидеров в других аспектах. Gemini 2.0 Thinking, несмотря на высокую архитектурную оценку, страдает от жесткой цензуры, что ограничивает её практическую применимость. Новая разработка от Perplexity, представленная в середине февраля, также продемонстрировала значительное улучшение и теперь составляет серьезную конкуренцию среди поисковых LLM.
Перспективы и доступность моделей
Среди новых разработок в области LLM значительное внимание привлекают модели от Perplexity, которые, благодаря активному внедрению инноваций, входят в число лидеров среди поисковых LLM. Grok 3 Reasoning и DeepSeek R1 представляют собой доступные решения, хотя и имеют свои ограничения: Grok 3 можно тестировать бесплатно в бета-режиме, а DeepSeek R1, будучи также бесплатным, страдает от частых сбоев. В то же время, такие мощные модели, как Claude 3.7 Sonnet Thinking и GPT-4.5, требуют значительно более консервативных финансовых вложений, что делает их менее доступными для широкой аудитории. GPT-4.5, будучи представителем нового поколения LLM, выделяется своей высокой стоимостью, что может ограничивать его распространение среди пользователей. Таким образом, в условиях растущей конкуренции и разнообразия моделей, доступность и стоимость становятся ключевыми факторами, определяющими выбор пользователей.
Заключение
Несмотря на свою высокую стоимость, GPT-4.5 продолжает оставаться конкурентоспособной среди LLM, не обладающих рассуждающими способностями. Высокие ценовые барьеры и наличие альтернатив, таких как Grok 3 и DeepSeek R1, ставят под сомнение её практическую ценность для конечного пользователя. Однако результаты тестирования подтверждают, что GPT-4.5 все еще занимает одну из ведущих позиций в категории LLM, что может быть связано с её уникальными возможностями в определенных приложениях.
Тем не менее, для более объективной оценки её эффективности в решении реальных рабочих задач требуется дополнительное тестирование и использование в разнообразных сценариях. Будущие обзоры помогут глубже понять, насколько конкурентоспособна GPT-4.5 в сравнении с другими моделями, что позволит лучше оценить её истинные преимущества и недостатки в различных контекстах.